ml-systemsobservabilitypythonanomaly-detectionincident-response
Notification Adjudication in My Ops Intelligence Agent: Canonical Events, Cheap Arbitration, and a Sender That Refuses to Spam
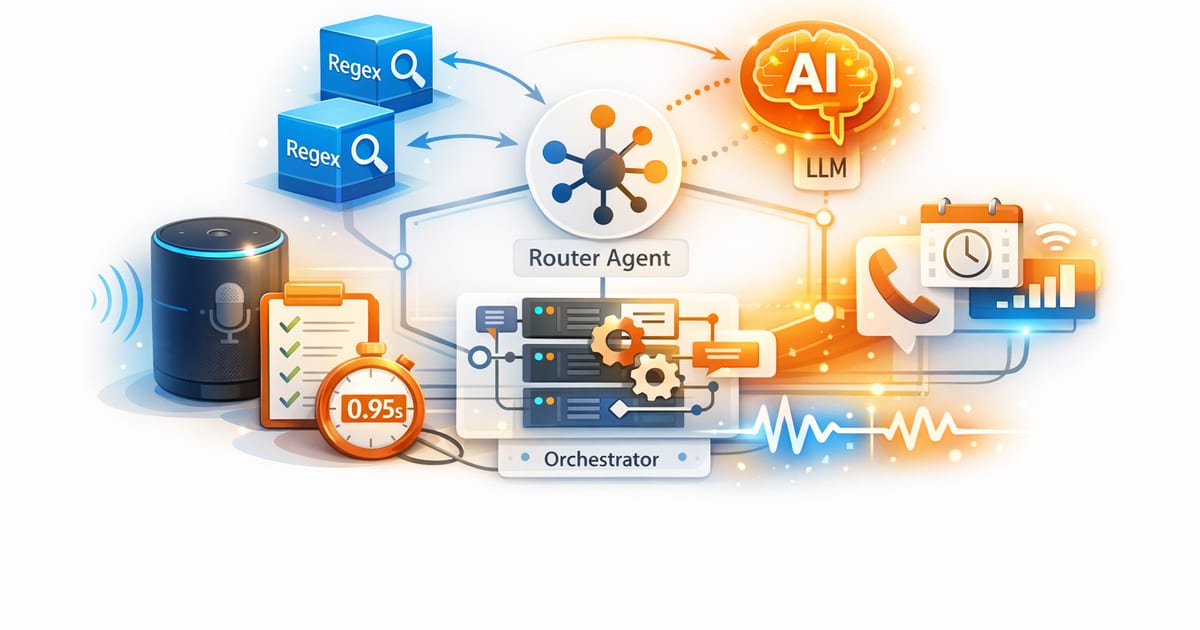
I built an Ops Intelligence Agent alongside a recruitment platform Operations Dashboard, to turn a noisy real-time event stream into a small number of Microsoft Teams notifications worth reading. The interesting part isn’t “sending a webhook.” It’s adjudication: normalizing heterogeneous telemetry, scoring it fast, collapsing duplicates, and dispatching defensively so the first alert lands quickly without setting off an alert storm.
Daniel Anthony Romitelli Jr. · July 28, 2026